系统首先维护的是本质而不是现象
Alan 2022-9-5 9:36
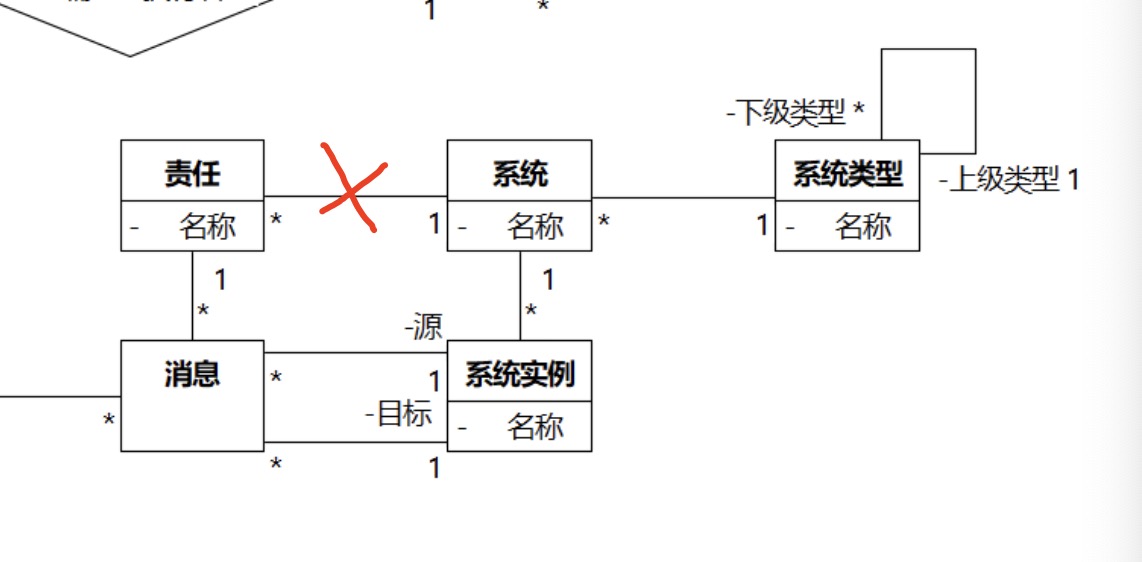
这个不用也可以 ,系统实例属于某个系统,某个实例上的责任,与哪个 源 无关。
UMLChina潘加宇
这个要的。系统有什么责任,这个才是本质的,你再仔细想想看
就是类图和序列图的关系。一定要砍的话,只能砍系统和系统实例之间的关联。
Alan 2022-9-5 9:53
是要的,只是说可以推算出来
UMLChina潘加宇
推算是从本质推算现象。系统-责任不需要依赖于系统实例-消息,反之则不然。
可以看这个。轮子的大小只依赖于轮子的属性,轮子的前后还要依赖车的结构约束。想想哪个更本质。
类似的还有,左拐弯,右拐弯,还是大拐弯,小拐弯
Alan 2022-9-7 9:46
在发糕的系统里,一个A系统的所有系统实例 的消息.责任 数量总和, 是不是与 A系统的责任 数量 相等呢?
UMLChina潘加宇
这个“所有实例”的数量可是无穷大了。
应该说,去掉重复元组之后,得到的结果是责任集合的子集。
******
这个问题问的实际上就是:
序列图上的消息是否覆盖了类的所有操作?
如果所有可能的场景都列出来,会的,否则,可能有一些操作很久很久以来都没有被用到。
也可以想想我们写过的所有代码(相当于“序列图上的消息”,string类有那么多方法,我们的代码中用到了其中多少个?
******
不过,从你问的几个问题来看,你的问题并不在这里。
系统首先维护的应该是没有任何冗余的本质模型,相同的信息在逻辑上只存在于一个地方。
虽然从各种“流水大数据”(条件是维护的数据全面的,像上面说的“有可能的场景都列出来”)来推算本质的模型系是可能的,但这个推算的逻辑也不是从天上掉下来的,也是先要理清楚本质的模型是什么,以及各种流水和本质模型的关系。
就像很多年前,我们面对各种各样充满冗余信息的纸质报表,对它们建模,找到本质的模型,这个过程很辛苦!但我们这样做就是要找到背后的本质规律,然后不用受二遍苦重复思考,需要报表时通过规律演算从本质模型得到报表。
就像科学研究一样,背后的物理规律没搞清楚时,可能要大量做实验,研究大量实验数据,拟合曲线等等。一旦找到其中规律,就没有必要从之前做试验的往的巨量数据来推测新数据了,我们只需记住探索出来的物理公式即可。
更何况,不是所有的系统都会保存“流水”。就像之前我写的那篇状态机文章中说的:
*有事件发生,未必需要记录事件(有A未必有B)电梯每天上上下下,不知发生多少次“召唤”事件,但是目前的电梯不会记录“召唤”事件的细节——谁召唤的、什么时候召唤的……,当然,也许有一天,电梯有了足够的计算和存储资源,会记录这一切。不记录事件,不代表事件没发生,更不代表事件没有产生效果。
******
现在那些鼓吹“事件溯源”的,以为逻辑是从天上掉下来的呢?
但凡认真学过关系代数而且成绩过关,就会对这些东西留个心眼,但现在很多开发人员,连这些基本的要求都达不到。
